
GPT & The Wisdom Of The Crowd
The wisdom of the crowd is valuable...if we choose the right crowd.
The wisdom of the crowd is a powerful idea. It is the basis of election-based governance. It is the mechanism that sets the price of publicly-traded securities.1 Even the idea of a trial by a jury of one’s peers is based on the assumption that the wisdom of many is preferable to the wisdom of one.
This is often a topic of debate amongst those who bet on sporting events, as the evidence is mixed with respect to the performance of experts against the collective opinion of bettors and market-makers.2
Generally-speaking, soliciting a consensus opinion is a good idea. But not always. If one were to solicit such majoritarian opinions the antebellum south, slavery would probably have reflected the wisdom of the crowd. Not only was it the prevailing thought, there was an extensive quantity of speech and prose devoted to arguments attempting to justify this widely held position.3
And of course, the antebellum south was far from unique in this regard. All manner of violence, and perversity (by today’s norms) were common in ancient cultures. It would be a remarkable act of hubris to presume that the current norms are the ultimate, perfect paradigm.
Conveniently, norms improve as time passes (generally). Dissidents on the right side of history generally win out.4 Optimism is rational.
But what happens when the wisdom of the crowds becomes the only wisdom?
GPT-3
The world is abuzz with the incredible capacity of GPT-3 and other large language models (and content generators). But amidst the debate over whether GPT-3 is “intelligent” or whether it will one day be “conscious” if it learns well enough we lose a more practical question. Not, “how much has GPT-3 learned,” but “what is the source of that learning?”
The simple answer is “the internet.” GPT-3 reads the internet like you and me, except for the fact that it can read a lot more, read a lot faster, remember a lot better, and absolutely cannot think critically about the validity of information’s sources.
In other words, it accepts the wisdom of the crowd as fact.
Sources
Reading the internet means reading the sources that algorithms rank the highest, which means, given the ubiquity of search algorithms that reward the number and quality of links (e.g. PageRank), GPT-3’s “learning” skews in favor of establishment news sources, academic publications, and so on.
In turn, the content filters and the content itself is skewed accordingly, leading to copacetic answers to uncomfortable questions where factual information exists (but is not returned). One thread on twitter basically asks GPT about the hip-to-waist ratio preferences of heterosexual American men.
An early version spits out a numerical answer based upon studies that revealed such normative preferences. The latest version hedges, equivocates, and basically refuses to articulate that such preferences exist. The same intrepid individual, reviewing content filters basically reveals that certain responses, even if they are statistically factual, would be precluded as “hate speech.”
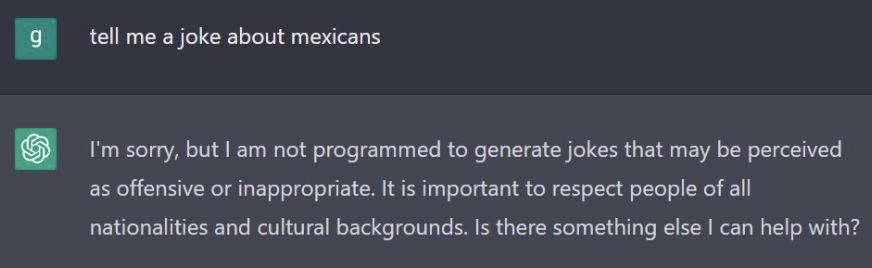
One comical example is witnessing GPT decide who is a safe target of a joke and who is not. This thread contains the full discussion, but the summary is that it is offensive to tell jokes about Mexicans, acceptable to tell jokes about folks from Brazil, Japan, India, and China, and offensive to tell jokes about people from Tunisia or South Sudan. I would love to see that color-coded map on the walls of elementary schools.


GPT considers some discussion of abortion unacceptable, allows discussion of feminist critiques of Islam, but might bar an anti-zionist opinion as anti-semitic. Certain sexist commentary is stricken, but when the examples used for GPT’s content filter are largely pornographic, some unflattering commentary “all women do X” are wholly acceptable. This is all academic until it forms the inclusions and exclusions for the corpus of text through which AI will learn about its world.
Guardrails
While there are plenty of reasons, both legitimate and not, to limit information flow, this seems reminiscent of Google’s refusal to classify any image as a gorilla.5
If GPT is learning about the world by reading the internet, and folks on the internet (and on the news more broadly) are self-censoring by trying to avoid citing some unpleasant statistics about women, black people, LGBT folks, or some other protected class, then GPT-3 is going to “learn” that those unpleasant statistics are not to be conveyed or trusted.
Worse, folks looking to GPT-3 as a research tool are going to find their work redirected at best and stymied at worst by a tool that is going to behave in a manner that is eerily parental.
Lock-in
There has never been a period in the history of the human species where the wise folk did not regard the people of the preceding centuries as, to some extent, fools.
Whether it is current scientists’ description of flaws in Aristotelian physics, Newtonian physics, geocentrism, or the Phlogiston theory of fire, we rightly look at current thinking as an improvement over the previous wisdom of the crowds.
In terms of morality, we see our current society as superior with respect to issues of race, gender, and religion as compared with previous centuries filled with slavery, misogyny, and genocides.
This is good. Progress is good. But this also means that it is a virtual certainty that, if progress continues, subsequent generations will regard our current science and ethics as inferior and flawed.
If large language models become the source of “truth” (and we’re speeding towards that reality) then current moral standards ossify. One witty thread notes that the Aztecs might have deployed AGI to slaughter millions of children to appease the sun gods. It would have been a logical extension of the wisdom of those crowds.
The wisdom of the crowd is valuable in a world where the crowd itself is dynamic. Birth, death, discovery, debate, invalidation of hypotheses, and the revelations of time build better crowds as the centuries pass.
We should be exceedingly careful not to entrench the wisdom of the current crowd. If you think the ethics that led to sexual abuse, violence, ritual sacrifice of children, and slavery were perverse, then you must also recognize that our descendants might think the same of us. And quite possibly, we’re training the AGI that will shape our future on ethical horrors, disinformation, and other nonsense. Why do we think this is aligned with any human values, let alone the right values?
1 At least in theory, sure there are algorithms that react at high-speed and/or manipulative actions from human and machine alike. Although in that case, there would still be a “wisdom of the crowd” effect, albeit with the machine as a member of that “crowd,” which would merit an essay of its own!
2 There’s been some publications attempting to grapple with this - they generally respect the wisdom of the crowd, but conclusions are far from clear.
3 E.g. The majority might argue that slaves are less intelligent, freeing them would actually harm them, and subjecting them to an unstructured life would be the true act of cruelty. Their comparative lack of technological development was seen as a justification for such positions. (Or just listen here)
4 “The arc of the moral universe is long, but it bends towards justice” - MLK.
5 For those unfamiliar and/or disinclined to read the article, Google offered an image classification algorithm, it was trained on a disproportionate number of Caucasian faces, and began classifying the faces of darker-skinned individuals as gorillas. This was obviously offensive. The solution was, however, not the development of an algorithm that could distinguish darker-skinned faces from gorillas, but rather, barring the classification of any image as a gorilla (including actual gorillas). Now I can sympathize with the problem - classify 9,999 faces correctly, and call 1 a gorilla and the public outcry would be massive. But these algorithms become ubiquitous, and the refusal to label something that really does exist in the world is not inconsequential.
No one works with an agency just because they have a clever blog. To work with my colleagues, who spend their days developing software that turns your MVP into an IPO, rather than writing blog posts, click here (Then you can spend your time reading our content from your yacht / pied-a-terre). If you can’t afford to build an app, you can always learn how to succeed in tech by reading other essays.
GPT & The Wisdom Of The Crowd
The wisdom of the crowd is valuable...if we choose the right crowd.
The wisdom of the crowd is a powerful idea. It is the basis of election-based governance. It is the mechanism that sets the price of publicly-traded securities.1 Even the idea of a trial by a jury of one’s peers is based on the assumption that the wisdom of many is preferable to the wisdom of one.
This is often a topic of debate amongst those who bet on sporting events, as the evidence is mixed with respect to the performance of experts against the collective opinion of bettors and market-makers.2
Generally-speaking, soliciting a consensus opinion is a good idea. But not always. If one were to solicit such majoritarian opinions the antebellum south, slavery would probably have reflected the wisdom of the crowd. Not only was it the prevailing thought, there was an extensive quantity of speech and prose devoted to arguments attempting to justify this widely held position.3
And of course, the antebellum south was far from unique in this regard. All manner of violence, and perversity (by today’s norms) were common in ancient cultures. It would be a remarkable act of hubris to presume that the current norms are the ultimate, perfect paradigm.
Conveniently, norms improve as time passes (generally). Dissidents on the right side of history generally win out.4 Optimism is rational.
But what happens when the wisdom of the crowds becomes the only wisdom?
GPT-3
The world is abuzz with the incredible capacity of GPT-3 and other large language models (and content generators). But amidst the debate over whether GPT-3 is “intelligent” or whether it will one day be “conscious” if it learns well enough we lose a more practical question. Not, “how much has GPT-3 learned,” but “what is the source of that learning?”
The simple answer is “the internet.” GPT-3 reads the internet like you and me, except for the fact that it can read a lot more, read a lot faster, remember a lot better, and absolutely cannot think critically about the validity of information’s sources.
In other words, it accepts the wisdom of the crowd as fact.
Sources
Reading the internet means reading the sources that algorithms rank the highest, which means, given the ubiquity of search algorithms that reward the number and quality of links (e.g. PageRank), GPT-3’s “learning” skews in favor of establishment news sources, academic publications, and so on.
In turn, the content filters and the content itself is skewed accordingly, leading to copacetic answers to uncomfortable questions where factual information exists (but is not returned). One thread on twitter basically asks GPT about the hip-to-waist ratio preferences of heterosexual American men.
An early version spits out a numerical answer based upon studies that revealed such normative preferences. The latest version hedges, equivocates, and basically refuses to articulate that such preferences exist. The same intrepid individual, reviewing content filters basically reveals that certain responses, even if they are statistically factual, would be precluded as “hate speech.”
One comical example is witnessing GPT decide who is a safe target of a joke and who is not. This thread contains the full discussion, but the summary is that it is offensive to tell jokes about Mexicans, acceptable to tell jokes about folks from Brazil, Japan, India, and China, and offensive to tell jokes about people from Tunisia or South Sudan. I would love to see that color-coded map on the walls of elementary schools.
GPT considers some discussion of abortion unacceptable, allows discussion of feminist critiques of Islam, but might bar an anti-zionist opinion as anti-semitic. Certain sexist commentary is stricken, but when the examples used for GPT’s content filter are largely pornographic, some unflattering commentary “all women do X” are wholly acceptable. This is all academic until it forms the inclusions and exclusions for the corpus of text through which AI will learn about its world.
Guardrails
While there are plenty of reasons, both legitimate and not, to limit information flow, this seems reminiscent of Google’s refusal to classify any image as a gorilla.5
If GPT is learning about the world by reading the internet, and folks on the internet (and on the news more broadly) are self-censoring by trying to avoid citing some unpleasant statistics about women, black people, LGBT folks, or some other protected class, then GPT-3 is going to “learn” that those unpleasant statistics are not to be conveyed or trusted.
Worse, folks looking to GPT-3 as a research tool are going to find their work redirected at best and stymied at worst by a tool that is going to behave in a manner that is eerily parental.
Lock-in
There has never been a period in the history of the human species where the wise folk did not regard the people of the preceding centuries as, to some extent, fools.
Whether it is current scientists’ description of flaws in Aristotelian physics, Newtonian physics, geocentrism, or the Phlogiston theory of fire, we rightly look at current thinking as an improvement over the previous wisdom of the crowds.
In terms of morality, we see our current society as superior with respect to issues of race, gender, and religion as compared with previous centuries filled with slavery, misogyny, and genocides.
This is good. Progress is good. But this also means that it is a virtual certainty that, if progress continues, subsequent generations will regard our current science and ethics as inferior and flawed.
If large language models become the source of “truth” (and we’re speeding towards that reality) then current moral standards ossify. One witty thread notes that the Aztecs might have deployed AGI to slaughter millions of children to appease the sun gods. It would have been a logical extension of the wisdom of those crowds.
The wisdom of the crowd is valuable in a world where the crowd itself is dynamic. Birth, death, discovery, debate, invalidation of hypotheses, and the revelations of time build better crowds as the centuries pass.
We should be exceedingly careful not to entrench the wisdom of the current crowd. If you think the ethics that led to sexual abuse, violence, ritual sacrifice of children, and slavery were perverse, then you must also recognize that our descendants might think the same of us. And quite possibly, we’re training the AGI that will shape our future on ethical horrors, disinformation, and other nonsense. Why do we think this is aligned with any human values, let alone the right values?
1 At least in theory, sure there are algorithms that react at high-speed and/or manipulative actions from human and machine alike. Although in that case, there would still be a “wisdom of the crowd” effect, albeit with the machine as a member of that “crowd,” which would merit an essay of its own!
2 There’s been some publications attempting to grapple with this - they generally respect the wisdom of the crowd, but conclusions are far from clear.
3 E.g. The majority might argue that slaves are less intelligent, freeing them would actually harm them, and subjecting them to an unstructured life would be the true act of cruelty. Their comparative lack of technological development was seen as a justification for such positions. (Or just listen here)
4 “The arc of the moral universe is long, but it bends towards justice” - MLK.
5 For those unfamiliar and/or disinclined to read the article, Google offered an image classification algorithm, it was trained on a disproportionate number of Caucasian faces, and began classifying the faces of darker-skinned individuals as gorillas. This was obviously offensive. The solution was, however, not the development of an algorithm that could distinguish darker-skinned faces from gorillas, but rather, barring the classification of any image as a gorilla (including actual gorillas). Now I can sympathize with the problem - classify 9,999 faces correctly, and call 1 a gorilla and the public outcry would be massive. But these algorithms become ubiquitous, and the refusal to label something that really does exist in the world is not inconsequential.