AI in the Brewery: How We Built a Beer with AI for Our Partners The Bruery
If AI could interact with the real world right now - smell the hops, touch the grains, taste the brew, can it, package it, and sell it - what would it make? To find out, we brainstormed with our longtime friends at The Bruery, one of the…


If AI could interact with the real world right now - smell the hops, touch the grains, taste the brew, can it, package it, and sell it - what would it make?
To find out, we brainstormed with our longtime friends at The Bruery, one of the most innovative breweries in the world (and a perennial favorite amongst beer aficionados), to see if we could use AI to brew a new beer that people would love.
The Bruery has brewed and bottled hundreds of beloved beers since its founding, including their annual, limited-edition Black Tuesday, and their #1 seller, Offshoot Relax. Could artificial intelligence create, brew, can, package design, and launch a beer that would stand up to those brews? Time to find out.
The Data
Our first goal was to develop an AI that could create recipes that would fit within The Bruery’s existing taste profile and brand. Much like a brew master might join a new brewery and get up-to-speed on the exact character of the brand, our model needed to be trained on the right data to generate valuable recipes.
Brewing data encompasses detailed records from various stages of the brewing process. This included:
- The Recipe: The “target recipe” to be followed, with values for gravity, specific grains, fermentors, and hops, the quantities for those ingredients, etc. This is a target because, similar to recipes in cooking, the brewer expects to deviate from the recipe based on the tiny, random variations that occur in the real world brewing process over different batches.
- Log Data: Detailed records of the brewing process for each batch of beer made using the recipe. This includes the ingredients used, process parameters like temperatures, times, the specific steps followed, and measurement values collected throughout the process like specific gravity, pH levels, ABV, etc.
- Brewtickets: Detailed documentation for a specific part of a batch, including the recipe being followed, process notes, observations and adjustments from the pre-brewing plan, the exact ingredients used for that exact batch, etc.
- Sensory Data: The information gathered from the sensory evaluation of beer. This uses specific human senses (taste, smell, sight, touch), and is the fun part of trying and evaluating the beer throughout the process. This can include things like flavor, aroma, appearance, and mouthfeel. It also includes how the beer is stored and its stability. These are collected at the end of brewing in "expert sensory panel sessions" multiple times after brewing. Their scores are from 1 to 5.
We wanted to have our AI brewer develop multiple recipes, of which The Bruery could then pick the most promising one to brew and try out.
The data was extensive, looking back at from 2020 to 2023 for The Bruery’s beers under the Offshoot brand: Escape, Drifting, New Beer Who Dis, Secret, and T-R-E-A-T.
The Architecture
Having lots of data was extremely promising, but also meant we had a lot of model features for the AI to consider. Each beer has multiple batches, and each batch had its unique characteristics, documented in meticulous detail.
The AI would be best at developing recipes if it could link the data of the recipes and process to the end sensory data results from the expert sensory panel. Put another way, if we told the AI we wanted good recipes, and it knew what past recipes had been tried and the sensory output (both good and bad trials), it could generate new and novel recipes that are likely to taste, smell, look, and drink great.
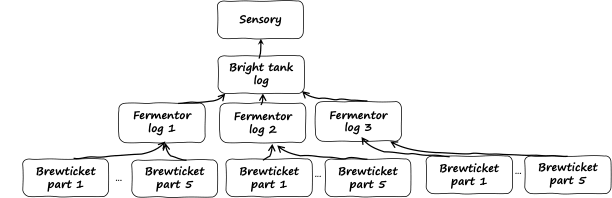
We first tried to interlink the sensory data with the brewing logs, but quickly faced a 'feature explosion' where the number of features skyrocketed. Additionally, we didn’t always have a clear one-to-one relationship between sensory data, logs, and brewtickets, as a single sensory evaluation could link back to multiple batches, and each batch could have data from several brewing stages. The number of inputs, relationship between the data, and sheer quantity of the data made it difficult to leverage all of that data for our AI to generate recipes.
Streamlining
What about a more streamlined approach?
In our next attempt, we tried to simplified things and streamline the data to focus on target recipe data directly. We ignored the more detailed brewtickets and logs, and narrowed in on elements like grain and hop types, gravity measurements, and packaging / storage. While developing the model, we met with our friends at The Bruery often to help interpret the data and hone in on the most impactful brewing parameters.

Luckily, the streamlined approach seemed much more promising as an architecture that would work. Confident, we moved to preparing the training data.
The Prep
Often, one of the most critical steps is data cleaning. This is not the sexy part, but is highly impactful for whether you’re going to have an AI that can accurately be trained on and learn from your data. We manually corrected typos, inputted missing data values, and discarded irrelevant features we knew wouldn’t matter. While these small errors are fine for human brewers, we needed the data to be clean for training our AI, because computers can’t handle and smooth over random inconsistencies the way we can as humans.
We also performed two other optimizations to help our model:
- Feature Combination: We knew we were targeting a Double West Coast IPA as the beer we wanted our AI to develop recipes for. This constrained the variety of hops and grains the AI could potentially use, so we were able to take advantage of this by merging types and quantities for the AI to consider in training, creating a more cohesive, focused dataset. There were specific quantities and combinations that simply didn’t make sense, so removing those let us better represent the relationship between ingredients and their quantities, reducing complexity.

- Data Augmentation: While we had a lot of data to work with, we still wanted more recipes to train on. We were able to augment the data by creating copies of the recipes, but with altered ingredient order. This wouldn’t impact the final product (which we validated with the team at The Bruery), but would provide the AI more examples of recipes to learn from.
After all data processing steps, we were ready to train.
The Training
We took all of the recipe dataset from 2020 to 2023 we'd cleaned, and had the AI predict the sensory scores of the various beer recipes. We trained and evaluated multiple models, selecting the top performers (xgboost, linear regression, and ridge regression) based on their ability to predict highly-rated beer recipes on a validation set.
Once we had models that performed well at accurately predicting a recipes sensory data, we turned towards developing new recipes. Leveraging the AI models by formulating an optimization problem (in this case, we used Differential Evolution) where our AI tweaked recipe characteristics to maximize the predicted sensory scores, we had the AI generate new recipes. The goal: generate recipes likely to score 4.8 or above in an expert sensory panel, with a special focus on unique, exceptional beer recipes.
For the unique, exceptional part of our goal, we compared recipes generated by our AI against each other and our training data. We wanted to identify recipes with distinctive combinations of grains and hops that were unique compared to the beers in the dataset.
Finally, we had our AI ensure (based on The Bruery’s team and the dataset) that all the recipes were realistic, with parameters that could be followed in the real world under the constraints of actual brewing processes.
The Gap
Along the way, we discovered an interesting gap in our AI’s ability to generate recipes: none of the underlying models successfully recognized the significance of hop time. This is an important part of the brewing process, and while we don’t yet know why this oversight occurred, we were able to develop a rule-based approach for the AI.
By following patterns observed in the training data, like the frequency of hop times, their association with specific hop types, and the number of hops involved in a given recipe, we gave the AI the rule-set it needed to account for hop time.
The Recipes
Finally, after multiple rounds of training and validating, it was time to see: how would an AI do in generating recipes?
We had our AI develop 7 of the best recipes it could for a Double West Coast IPA, and The Bruery reviewed them. All of them looked promising, with two in particular standing out.
The Bruery took those recipes, made some small tweaks, and brewed them!
The outcome?
Of those two, one of the recipes is A.I.P.A., our AI brewed IPA. A hoppy, dank, piney and incredibly drinkable IPA, it's delicious. We've gotten rave reviews so far - go buy this beer right now!

The other? Well, you might see it someday soon.
What’s Next?
With an AI architecture that we know works, we think we can leverage our new AI brewer to develop other styles of beer, making the AI more flexible and more of a generalist.
As for the other parts of the business, we leveraged AI to collaboratively generate the can artwork above, and the marketing copy. That was a really fun process, and we’ll share more on this in a follow up post.
Interested in leveraging our AI, its expertise, or AE's skills for your own business? Drop us a line, we’d be happy to chat: aipa.ae.studio.
Thanks to The Bruery/Offshoot Beer Co for this amazing collaboration, especially Kelli and Dustin for working closely with us. A special thanks as well to Ethen, Brendan, and Justin.
A big shout our as well to the AE Studio team, including José, Husam, Bruno, Larusso, Daniel, Mason, Ershad and Arun.