Why Do We Make Bad Decisions Despite the Data?
Why fear and myopia keep data scientists awake at night...
Little League was a fixture in my somewhat idyllic childhood. Father coached the team, chided his offspring for lapses in fundamentals, and instilled a love of baseball that ultimately led to the development of algorithms for wagering upon the performances of professionals. Degeneracy might not have been the original intent, but it did lead to a career in data science, which given my father’s 4+ decades teaching high school mathematics, seems a bit like Dr. Frankenstein’s joining the family business (“it’s pronounced Fronkensteen”).
Images of bucolic exurbs filled with kids in caps and cleats are hardly the stuff of nightmares unless the dreamer recently watched Children of the Corn. But as a child, I was continually haunted by them because of the mere possibility of a strikeout. So afraid of striking out, I shortened my swing, then pathologically focused upon improving eye-hand coordination by repeatedly hurling a tennis ball against basement wall panels from ever-decreasing distances and attempting to catch said ball (also shattered a few light fixtures in said basement...). In turn, a child of unusual timidity and tenacity manages to complete seasons of Little League without a single K penned in the father’s scorebook. Of course, the child also grounds out harmlessly with a Mendoza-esque-frequency and, like most dorky adolescents, rarely reaches second base. A conservative swing is unlikely to produce any outcome other than a single past the age at which some disinterested kid is picking dandelions and/or nostrils in right field.
The strikeout’s cost is obvious in terms of the negative outcome upon the field of play. The cost of risk-aversion is likely greater, unmistakably quantifiable, and yet, often invisible. There’s the rub. The stuff of data scientists’ nightmares is the black hole into which these invisible costs are sucked, an event horizon beyond which all costs are sunk.
Your humble blogger is of diminutive stature, and thus spent his youth with a tennis racquet in hand in addition to a baseball bat. Like the national pastime, tennis presents a simple paradigm in which visible costs, psychological harm, and disapprobation of the crowd overwhelm optimal strategy. Every point begins with an aggressive strike (first serve), which if unsuccessful, is followed by a more conservative offering (second serve). The latter offers a higher probability of success and a lower reward. But this is not the calculus of an athlete clad in white and plying their trade before some combination of kings, queens, and immaculately-coiffed celebrities. A timid second-serve, even if it gets creamed, avoids horrified groans and gasps between bites of strawberries and cream. A double-fault does not. Does the math justify such things? Let’s ponder.
First, we define some relevant parameters:

Sometimes data scientists generate dizzying complexity. Sometimes algebra gets the job done! Never solve a complicated problem when a simpler one suffices. And remember, p * w connotes the probability of getting one’s serve in play and winning the point.
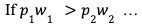
We can conclude that hitting the first serve with no safety net is a higher value proposition than the “safer” second offering because the probability of winning the point if the first serve succeeds is so much higher. Fortune favors the brave, even if the brave happen to be wearing a collared shirt for an athletic contest.
In other words, “don’t hit your second serve, hit your first serve again. Damn the torpedoes (and the disapproving celebrity onlookers), full speed ahead!”
Surely (and yes, I called you ‘Shirley’), there cannot be a top-50 professional on the ATP or WTA tours where the statement above is true? There are. In fact, two players on the ATP and WTA tours respectively, in the top 50, fail that basic test. But this is the tip of the iceberg–how many hours do professional athletes spend practicing a skill that presents either negative expected value or minimal lift? How much improvement could be extracted from p1w1 if we ceased efforts focused upon p2?
Even if p1w1 could be increased by a mere 3%, suddenly nine men and eight women would be better off scrapping the second serve altogether. Perhaps the tempestuous petulance of Nick Kyrgios isn't so ill-considered? But remember, is the goal to maximize the number of points won or avoid the scorn of the royal box?
Why such digressions about sports? Why fixate upon the insecurities of a tiny adolescent or a muscular racquet-wielder withering under watchful eyes? Because the costs of risk aversion are largely invisible (until the cold, calculating eyes of a data scientist fixes their gaze thereupon).
In the private sector, we do not contend with such solitary experiences as the batter’s box or the second serve. Or do we?
Nascent entities often recognize the short-term value of outreach campaigns. Mass emails are ostensibly free, and the conversion rates they yield are small, but decidedly larger than zero! Easy money: just load some gunpowder into the spam cannon, aim, and fire! Heck, if you have sales targets to hit, skip step two!
Of course, if you send 100K emails this month, some of those folks will cut you a check. It won’t be many, but even a blind Nigerian prince will find a few acorns and mixed metaphors to squirrel away for winter. Yet, as AE’s work on ElectricSMS proved, diminishing agency by worsening customer experiences is a qualitative problem with quantifiable effects! Many more of those 100K recipients will tweet horrible things about your unsolicited spam, decry your lack of creativity on Yelp, or worse, unsubscribe! A few more of those leads will grow incrementally icier, like my Chicagoland home in autumn or the disposition of a humorless reader of this soliloquy.
Ok, more math:

In this regard, the lifetime value of a given lead is calculated as:
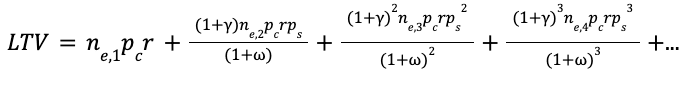
Some of you may recall the simplification of an infinite, decaying series. Others of you will not recall this simplification, but recall that at one point, you did recall said simplification and take some solace therein. And others will cringe at even the parsing of the clause containing words like simplification, infinite, and decaying. Mercifully, if we assume a consistent number of emails per month per lead (and for what’s left of my sanity, can we please?), call it n, and apply the simplification here:
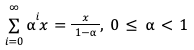
we obtain1:

Of course, the revenue generated in the first month is just a wee bit easier:

Just multiply the number of leads to spam by the number of emails per recipient by the conversion rate, by the revenue per conversion. Easy.
Ready for the ultimate set of black-holed losses, the type that keeps this tortured data scientist tossing and turning in his midwestern bed?
What happens if we send 10% fewer spam emails? This is easy algebra:
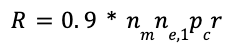
The “costs” are as easy to observe as a strikeout, a double-fault, or any other such ignominious event. So of course, as the boardroom discussion occurs around a table of rich mahogany with expensive, circumambient leather chairs, clearly, we cannot decrease the outreach.
Of course, intuitively, we know that spam decreases the probability a lead survives until next month, ps (bad!), decreases their engagement/growth if they do survive, (very bad!) and lowers conversion rates, pc (really, really bad!). Thus, the LTV of the universe of leads will be diminished. But that, alas, is like the cost of a weak ground ball to second or a pulverized second serve. That cost is real, but prove that from the seat of the aforementioned voluptuous chair. Sure, you’ll need to send 150K emails the following month to compensate, and sure, before you know it, the outreach will hit orders of magnitude reserved for the number of quantum particles in the universe. But those costs will remain ephemeral, intangible, and most importantly in business, someone else’s problem.
Fellow travelers in the world of data science, enterprise strategy, and human agency, transcend the insecurity of the awkward adolescent within. Let the queen scoff at a double fault. Be long-term greedy even when the short-term costs are readily apparent. Spare me from my nightmares (or invent an algorithm designed to provide therapy to verbose data scientists)!
1
To quote Charlie Daniels, “if you care to take a dare, I’ll make a bet with you.” If you differentiate aptly kid, you’ll see what devils are due - just take the LTV, then try dL/dp and the costs emerge for you!
You can try differentiating the LTV with respect to survival rate, conversion rate, or growth rate, and in every case, you’ll note that the decline in value is significant, and the bleeding can only be addressed by sending more emails the next month than the preceding month. Incidentally, this is massively damaging to human agency, as the barrage of emails and SMS cripple focus and efficiency.