
Neglect
Some ideas are prematurely discarded. Bayesian reasoning suggests this is a terrible error.
Doing anything for the first time typically results in failure. The first combustion engine probably sputtered and failed quickly (if it sputtered at all). The first computer failed every time a bug flew into one of its vacuum tubes. The first attempt to build a functioning spreadsheet is usually riddled with logical errors in the calculations, let alone complex software, let alone the first algorithm whose generalized intelligence exceeds that of a human being.
Mistakes are inevitable.
And this, fundamentally, is the argument put forth by Eliezer Yudkowsky’s Machine Intelligence Research Institute (MIRI). AGI is going to arrive. The first iteration will be flawed because the first iteration of everything is flawed.
But AGI is neither an automobile nor a spreadsheet. The initial failures, rather than becoming roadside inconveniences or embarrassing errors in the conference room, might yield an intelligence with misaligned objectives that kills or tortures humanity permanently.
The Polemicist
This type of thinking is intellectually coherent, but largely fatalistic. It is empirically true that the first attempt at anything rarely succeeds. It is also at least logically plausible that the first attempt to build an appropriately aligned AGI will fail. That failure is likely to present disastrous consequences.
Unfortunately, this line of thinking is juxtaposed with its author’s adage about the weak links of complex beliefs:
“When you profess a complex belief, each detail is another chance for the belief to be wrong. Each specification adds to your burden. Lighten your load when you can. A chain of a thousand links breaks at a single point of weakness. Be careful on every step.”
When this logic is extended, AGI alignment is an unsolvable problem, we have already crossed the Rubicon, and the only thing left to do is either some Draconian attempt at collective action wherein every government of the world agrees to ban AGI research and rigidly monitors the usage of GPUs1 or accepts inevitable, untimely death.
Worse, any attempts to solve alignment are complex (it’s a complex problem) and require a sequence of intellectual and technical achievements. These are the proverbial “links in the chain” to which Yudkowsky refers. It is likely that one of the links will be flawed, the idea will fail, alignment will not be solved, and we’ll all die.
Adding slightly more nuance and detail to the previous line of argument, Yudkowsky asserts that even without a specific scenario that poses an existential risk, there are several challenges that must be overcome to avoid AGI ruin, and that the probability of navigating the gauntlet of all such challenges is miniscule.2
The Bayesian
Yudkowsky fancies himself as a rationalist, but also, famously, a fan of Bayesian reasoning. And unfortunately, absent Bayesian reasoning, some horrible conclusions are reached.
Let’s do some math.
Imagine a chain with 1,000 links. If any one of them is broken, the chain snaps and horrible things happen. Let’s imagine that the probability of any link being structurally unsound is ~0.5%. What’s the chance that the chain will hold?
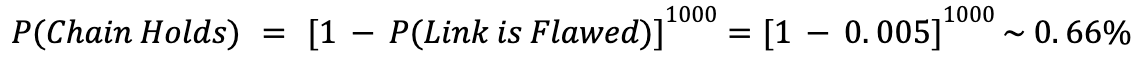
The chain will probably break. That makes sense, since the odds of a link breaking are 1 in 200, and there are 1,000 links. But maybe it won’t break, and something that offers a 0.66% chance (~150:1 odds) of solving alignment and saving humanity is probably worth pursuing.
But now what happens when Yudlowsky applies his “weak link” detector? We’ll give that tool some probabilities from which to build.
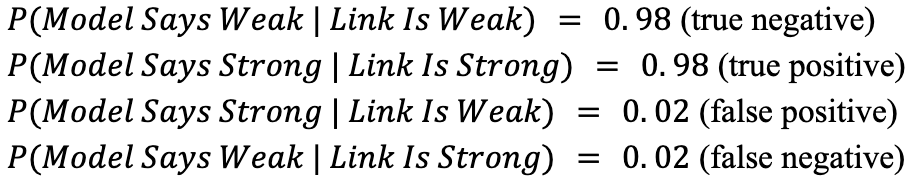
Basically, the tool errs 2% of the time (which is probably conservative when assessing novel areas of inquiry and the underlying, untested assumptions made).
Therefore, in a 1,000 link chain, we expect 5 flawed links (0.005 * 1,000) and 995 strong links. We then expect our detector to report:
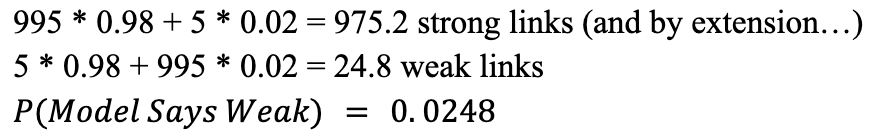
Now, using Bayes’ rule:
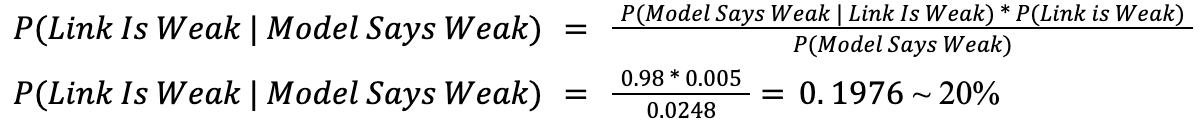
So basically, even when the detector reports that a link is weak, the probability that the link actually is weak is still a hair below 20%. This means that when we identify what we believe to be a weak link (and discard the entire line of reasoning as a result), we are most likely doing so in error. What if that was the approach that could solve alignment?
Why does this matter so profoundly?
The Discordant3 Conclusion
Let’s say we apply the “detector” (e.g. the best intuitions and insights from the broader intellectual community) to 1,000 links. What is the probability that we report that the chain will hold?
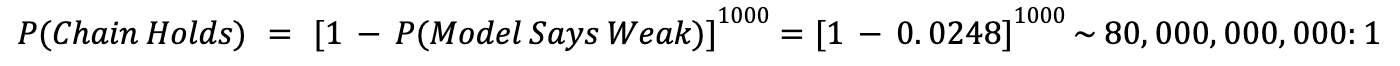
Now the probability that a chain holds is 80 billion to 1 according to folks with MIRI-like logic.4 Better just hold your loved ones close and await the end.
And while Bayesian reasoning illustrates that more than 80% of the links that our intuition suggests are weak are probably viable components of a larger solution, we still behave as if we are most assuredly (minus the 80 billion to 1 moonshot) doomed.
AE, AGI, and Neglect
AE is a profitable, bootstrapped, for-profit business. Taking on neglected problems lives in our DNA. We believe that approaches that the world perceives as being highly-improbable paths to solve alignment might very well be orders of magnitude more promising than the broader perception of them.
This is why, despite the EA community’s general perception of consciousness-related research and its orthogonal relationship with machine intelligence, AE suspects that a conscious AGI may be a path to prosociality rather than sociopathy. While other researchers may dismiss this approach despite its significant potential merit, AE sees a richer understanding of the motor cortex and peripersonal space and their potential machine representations as a neglected approach that might ultimately teach AGI to empathize and relate to humans in a manner that might increase our odds of solving alignment.
While LLMs are being written and distributed on a daily basis, we are penning award-winning manuscripts on their potential vulnerabilities. While most technical professionals in the AGI alignment space are trained as ML researchers, AE is leveraging its stable of world-class developers and ML professionals to do more hustling and less philosophizing, considering that nobody has managed to solve alignment yet and timelines are short. An entrepreneurial disposition leaves us unafraid of neglected ideas with low probabilities of success that hide untapped potential, and we believe our unique structure allows us to capture and execute these ideas both rapidly and responsibly.
While most entities are beholden to the venture capitalists who fund their efforts or the entities that define which grants are funded, AE’s financial incentives are unfettered - we simply wish to maximize human agency (as we do with all projects) by minimizing the probability of X-risk from a misaligned AGI.
Hope
We hope that our core values and our simple approach - steelman, calculate, refute, iterate, and improve are the epistemic path to solutions others might overlook. In fact, this essay is a microcosm of that very line of thinking.
We do not disregard ideas because they have been deemed unfit for exploration by the broader community. Moreover, it is likely that if humanity is to locate future-altering solutions to problems posing existential risks, it will be a neglected approach that yields the answer.
Why? Because the math above illustrates that almost any dismissal of an argument as a function of “weak link” reasoning (which seems to be the prevailing paradigm for MIRI and broader AGI research efforts) likely excludes any approach with a low, but non-trivial probability of success. How many such approaches exist? How many remain unexplored?
When considering the potential for groundbreaking research or entrepreneurship, especially when the consequences of failure seem unusually steep, we often insist that the approach be wholly unique from anything attempted previously. This requires that anything perceived as having been tried never receives the iterations of baby-step improvements that might ultimately bear fruit. Neglected approaches are almost by definition, those that we believe have a low probability of becoming the ultimate, right answer.
Yet we often discard them where AGI alignment research can all-too-easily converge on an unnecessarily narrow set of approaches. Innovators and entrepreneurs are dispositionally-suited to challenging the status quo. And it is this mindset that is crucial for the exploration and progress AGI demands.
It is this uncharted territory that AE pursues on behalf of its clients and humanity more broadly.
1 And enforces this agreement with military action against physical locations of servers on the sovereign soils of the non-compliant!
2 Because solving any such challenges requires several links in an epistemic chain, and thus, solving all of them requires every link of every chain to hold, and of course this is improbable, and down the doom loop we go…
3 Because “the repugnant conclusion” is already taken.
4 Kinda like the Dr. Strange meme about a 1 in 14,000,065 chance to defeat Thanos, but for real.
No one works with an agency just because they have a clever blog. To work with my colleagues, who spend their days developing software that turns your MVP into an IPO, rather than writing blog posts, click here (Then you can spend your time reading our content from your yacht / pied-a-terre). If you can’t afford to build an app, you can always learn how to succeed in tech by reading other essays.
Neglect
Some ideas are prematurely discarded. Bayesian reasoning suggests this is a terrible error.
Doing anything for the first time typically results in failure. The first combustion engine probably sputtered and failed quickly (if it sputtered at all). The first computer failed every time a bug flew into one of its vacuum tubes. The first attempt to build a functioning spreadsheet is usually riddled with logical errors in the calculations, let alone complex software, let alone the first algorithm whose generalized intelligence exceeds that of a human being.
Mistakes are inevitable.
And this, fundamentally, is the argument put forth by Eliezer Yudkowsky’s Machine Intelligence Research Institute (MIRI). AGI is going to arrive. The first iteration will be flawed because the first iteration of everything is flawed.
But AGI is neither an automobile nor a spreadsheet. The initial failures, rather than becoming roadside inconveniences or embarrassing errors in the conference room, might yield an intelligence with misaligned objectives that kills or tortures humanity permanently.
The Polemicist
This type of thinking is intellectually coherent, but largely fatalistic. It is empirically true that the first attempt at anything rarely succeeds. It is also at least logically plausible that the first attempt to build an appropriately aligned AGI will fail. That failure is likely to present disastrous consequences.
Unfortunately, this line of thinking is juxtaposed with its author’s adage about the weak links of complex beliefs:
“When you profess a complex belief, each detail is another chance for the belief to be wrong. Each specification adds to your burden. Lighten your load when you can. A chain of a thousand links breaks at a single point of weakness. Be careful on every step.”
When this logic is extended, AGI alignment is an unsolvable problem, we have already crossed the Rubicon, and the only thing left to do is either some Draconian attempt at collective action wherein every government of the world agrees to ban AGI research and rigidly monitors the usage of GPUs1 or accepts inevitable, untimely death.
Worse, any attempts to solve alignment are complex (it’s a complex problem) and require a sequence of intellectual and technical achievements. These are the proverbial “links in the chain” to which Yudkowsky refers. It is likely that one of the links will be flawed, the idea will fail, alignment will not be solved, and we’ll all die.
Adding slightly more nuance and detail to the previous line of argument, Yudkowsky asserts that even without a specific scenario that poses an existential risk, there are several challenges that must be overcome to avoid AGI ruin, and that the probability of navigating the gauntlet of all such challenges is miniscule.2
The Bayesian
Yudkowsky fancies himself as a rationalist, but also, famously, a fan of Bayesian reasoning. And unfortunately, absent Bayesian reasoning, some horrible conclusions are reached.
Let’s do some math.
Imagine a chain with 1,000 links. If any one of them is broken, the chain snaps and horrible things happen. Let’s imagine that the probability of any link being structurally unsound is ~0.5%. What’s the chance that the chain will hold?
The chain will probably break. That makes sense, since the odds of a link breaking are 1 in 200, and there are 1,000 links. But maybe it won’t break, and something that offers a 0.66% chance (~150:1 odds) of solving alignment and saving humanity is probably worth pursuing.
But now what happens when Yudlowsky applies his “weak link” detector? We’ll give that tool some probabilities from which to build.
Basically, the tool errs 2% of the time (which is probably conservative when assessing novel areas of inquiry and the underlying, untested assumptions made).
Therefore, in a 1,000 link chain, we expect 5 flawed links (0.005 * 1,000) and 995 strong links. We then expect our detector to report:
Now, using Bayes’ rule:
So basically, even when the detector reports that a link is weak, the probability that the link actually is weak is still a hair below 20%. This means that when we identify what we believe to be a weak link (and discard the entire line of reasoning as a result), we are most likely doing so in error. What if that was the approach that could solve alignment?
Why does this matter so profoundly?
The Discordant3 Conclusion
Let’s say we apply the “detector” (e.g. the best intuitions and insights from the broader intellectual community) to 1,000 links. What is the probability that we report that the chain will hold?
Now the probability that a chain holds is 80 billion to 1 according to folks with MIRI-like logic.4 Better just hold your loved ones close and await the end.
And while Bayesian reasoning illustrates that more than 80% of the links that our intuition suggests are weak are probably viable components of a larger solution, we still behave as if we are most assuredly (minus the 80 billion to 1 moonshot) doomed.
AE, AGI, and Neglect
AE is a profitable, bootstrapped, for-profit business. Taking on neglected problems lives in our DNA. We believe that approaches that the world perceives as being highly-improbable paths to solve alignment might very well be orders of magnitude more promising than the broader perception of them.
This is why, despite the EA community’s general perception of consciousness-related research and its orthogonal relationship with machine intelligence, AE suspects that a conscious AGI may be a path to prosociality rather than sociopathy. While other researchers may dismiss this approach despite its significant potential merit, AE sees a richer understanding of the motor cortex and peripersonal space and their potential machine representations as a neglected approach that might ultimately teach AGI to empathize and relate to humans in a manner that might increase our odds of solving alignment.
While LLMs are being written and distributed on a daily basis, we are penning award-winning manuscripts on their potential vulnerabilities. While most technical professionals in the AGI alignment space are trained as ML researchers, AE is leveraging its stable of world-class developers and ML professionals to do more hustling and less philosophizing, considering that nobody has managed to solve alignment yet and timelines are short. An entrepreneurial disposition leaves us unafraid of neglected ideas with low probabilities of success that hide untapped potential, and we believe our unique structure allows us to capture and execute these ideas both rapidly and responsibly.
While most entities are beholden to the venture capitalists who fund their efforts or the entities that define which grants are funded, AE’s financial incentives are unfettered - we simply wish to maximize human agency (as we do with all projects) by minimizing the probability of X-risk from a misaligned AGI.
Hope
We hope that our core values and our simple approach - steelman, calculate, refute, iterate, and improve are the epistemic path to solutions others might overlook. In fact, this essay is a microcosm of that very line of thinking.
We do not disregard ideas because they have been deemed unfit for exploration by the broader community. Moreover, it is likely that if humanity is to locate future-altering solutions to problems posing existential risks, it will be a neglected approach that yields the answer.
Why? Because the math above illustrates that almost any dismissal of an argument as a function of “weak link” reasoning (which seems to be the prevailing paradigm for MIRI and broader AGI research efforts) likely excludes any approach with a low, but non-trivial probability of success. How many such approaches exist? How many remain unexplored?
When considering the potential for groundbreaking research or entrepreneurship, especially when the consequences of failure seem unusually steep, we often insist that the approach be wholly unique from anything attempted previously. This requires that anything perceived as having been tried never receives the iterations of baby-step improvements that might ultimately bear fruit. Neglected approaches are almost by definition, those that we believe have a low probability of becoming the ultimate, right answer.
Yet we often discard them where AGI alignment research can all-too-easily converge on an unnecessarily narrow set of approaches. Innovators and entrepreneurs are dispositionally-suited to challenging the status quo. And it is this mindset that is crucial for the exploration and progress AGI demands.
It is this uncharted territory that AE pursues on behalf of its clients and humanity more broadly.
1 And enforces this agreement with military action against physical locations of servers on the sovereign soils of the non-compliant!
2 Because solving any such challenges requires several links in an epistemic chain, and thus, solving all of them requires every link of every chain to hold, and of course this is improbable, and down the doom loop we go…
3 Because “the repugnant conclusion” is already taken.
4 Kinda like the Dr. Strange meme about a 1 in 14,000,065 chance to defeat Thanos, but for real.