
Settling Arguments With Baseline Expectations
Adjusting your baseline expectations could relieve your fantasy football woes. A data scientist explains why you should take a new approach to this season's draft.
This is a sigmoid function:
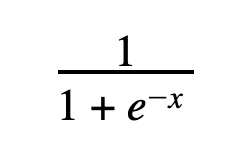
Why the hell should anyone care about sigmoid functions? After all, we’re talking about some little exponential in a denominator. To most, it resembles what you might see before you fall asleep, begin texting, ogling that member of your statistics class, or entering catatonia from one-too-many horrific note-taking experiences. The answer, apart from “because I said so,” “because you’ll make more money someday if you do,” and “because failing tests and retaking classes generally sucks,” is that it can help settle arguments. No, seriously.
For the data scientists in the audience, the sigmoid function might be a quaint reminder of the early days of neural networks—back when deep learning meant preparing for an essay on Faulkner rather than the sound and fury of AI-obsessed VCs...or the building block of perceptrons and other activation functions. But we’re talking to the other folks in the crowd. You may also remember its roles in such films as logistic regressions, cumulative distribution functions, and softmax. Schedule a call to hear our data scientists reminisce more.
For those of us who drink beer and watch football on Sundays, who pronounce the word ‘sandwich’ with two ‘ms’ and no ‘w,’ sigmoids are simple little functions that typically traverse the well-worn path from 0 to 1, slowly, then abruptly, then slowly again.
They look like this:

Sigmoids settle arguments. Why? Because they encourage us to consider what “should have happened” rather than what did. The totality of any sports bettor’s tortured existence can be summarized as a litany of things that were likely that did not occur, or things that are unlikely, but occurred nonetheless. Fantasy football generates such arguments multiple times weekly throughout football season and rends lifelong friendships with such rationalizations. In other words, everyone claims they were unlucky and their opponents were blessed with an embarrassment of riches in the form of fortuitous breaks. But such discourse is tedious to the football fanatic turned data scientist. And thus, as the commissioner of one particular league since 2010 (I entered the league in the fall of 2004, back when we’d assemble on the stained couches of some dorm, select players, then manually send the results to Yahoo via a badly-frayed ethernet cord), I took it upon myself to address this issue.
For those who spend their weekends doing useful things around the house or engaging affably with significant others and spouses (my apologies to my wife), fantasy football is fairly simple. Teams are filled with real-life players, and from their weekly performances, points are amassed. Each week, within a league, teams face a single opponent, and the team with the higher number of points wins. At this point various forms of derision regarding the vanquished opponent’s intelligence and the corporal attributes of their mother are customary.
Now, in a league with twelve teams, how well one’s team plays is often secondary to who one’s team plays. The team with the 2nd-highest score in a league on a given week is still tagged with a loss (and the aforementioned insults regarding their mother) if they are unfortunate enough to be matched with the team that earns the week’s highest score. Conversely, the team with the 2nd-lowest score is still empowered to disparage to their heart’s content if they are fortunate enough to face the team with the week’s lowest score.
As the season unfolds, these narrow escapes and “bad beats” form a narrative wherein there are not only winners and losers, but also those upon whom fortune has smiled and those upon whom the ominous, darkened clouds surrounding the accursed have gathered. Somewhere, after a couple potent potables on a cold, December night, invariably, some group email is penned regarding the continued (read: unfair) luck of one such roster and the continued (read: unfair) misfortune of their own.
What if, amassing samples of previous games, we could determine the “true” probabilities of a team winning its weekly matchup, given a certain number of points scored? What if, in so doing, we removed the vicissitudes of who played whom when? This would reveal the “true standings,” that is, those produced in a fairer world. So perhaps this is not the “best of all possible worlds,” but then, Voltaire never played fantasy football.
Every week, games occur, points are amassed, and, ultimately, wins and losses are assigned. Much like a logistic regression aspires to select a probability based on binary outcomes, a sigmoid function is fit to historical scores and the wins and losses they generated. Below are the results from two years of the aforementioned fantasy football league:

The red dots represent the scores of individual teams, where the outcome was a loss. The blues denote wins. What pattern appears? Clearly, the red dots generally occur at lower values than the blue dots (“duh, higher scores are more likely to win”). However, as Damon Runyon once said (stealing the words of Hugh Keough, who in turn was basically cribbing from Ecclesiastes), “the race is not always to the swift, nor the battle to the strong, but that is the way to bet!” So, if we look at the dots between 140 and 160 points, most are blue. If we look at the dots between 80 and 100, most are red. But it is these expectations that spark incendiary commentary and the type of angst that lingers for years in the minds of the fanatical. When your team scores 130 points, you expect to win. When your rival scores 90, you expect him or her to lose. Yet, there are blue dots around 90 and red dots around 130. And thus begin soliloquies on the injustice of it all.
So what do we do about this? Well, we do the thing that data scientists do—we build a model. Adding a nugget of complexity to our humble sigmoid, we fit the following:
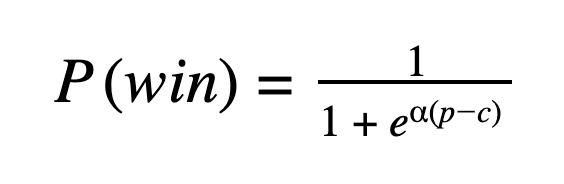
In the equation, p denotes the number of points scored, c, the center of the sigmoid (that is, the point at which the probability is 0.5), and 𝜶 essentially describes how steeply the curve ascends as we move from left to right.

In turn, every score corresponds to a probability of winning—and we assign each team that number of wins. In the chart below, a score of 125 points yields around a 75% probability of victory. And thus, we assign that team 0.75 “true wins,” rather than the 0 or 1 that are actually obtained. We do this all season long and two quantities emerge:
- The “true standings” - each team’s record, in a truly just world is easily obtained after n games have been played, each with points scored pi, via:
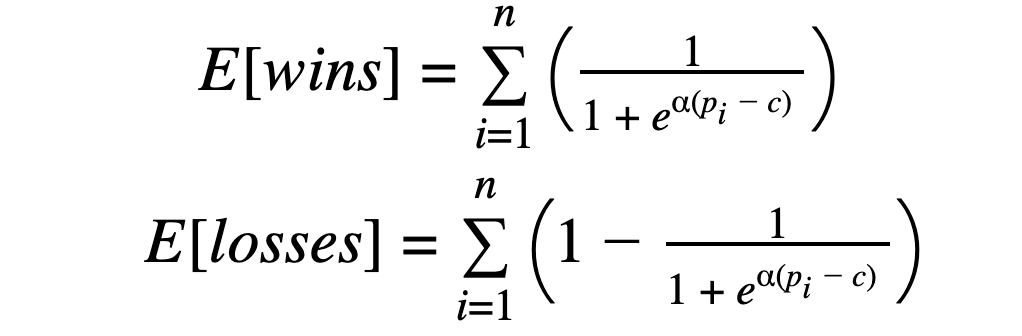
2. The aggregated “luck,” positive or negative, of each roster (wins above expectation), after n games, is simply:
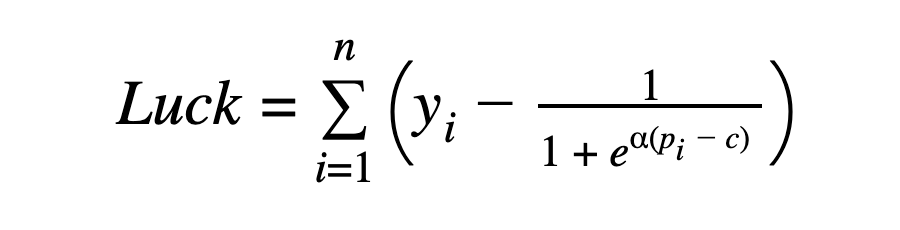
Where:
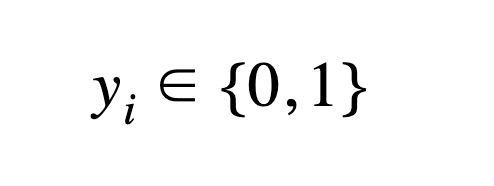
In this case, the values of yi simply represent what actually happened (1 for a win, 0 for a loss).
For example, one Sunday, your team scores 125 points...and wins. The value for E[wins] is ~0.75, the value for E[losses] is ~0.25. The value for yi is 1 (you really did win), and “Luck” is now 1 - 0.75 = 0.25. Had you lost, would have been 0, “Luck” would have been 0 - 0.75 = -0.75. Just as you earn expected wins, you amass expected luck (or “unluck” in the case of a negative value).
Why does this matter, apart from minimizing sordid condemnations of maternal virtues? Because entities in the “real world,” (you know, the ones tasked with generating profits rather than winning fantasy football games) fixate on what happened with little consideration for the relative likelihoods of alternative outcomes. Even in a world awash in data scientists, engineers, and dozens of other titles containing some variant of the word “analytics,” we are drawn inexorably to the outcomes we observe.
Once, during my young adult delinquency (as a corporate consultant), I found myself managing a couple young analysts on a project, during which a client was assessing the efficacy of salespersons. In some regards, salespeople were, are, and will continue to be judged on the number of deals they close relative to the number they attempt to close, rather than the likelihood of closing the deal as a function of the price offered to the prospective client. To wit, if the salesperson gives away the farm in the form of an extremely generous price, the client is more likely to say yes than if they hold the line. Counting wins and losses in such an environment is akin to evaluating an Olympic gymnast without considering the routine’s degree of difficulty (imagine some Micronesian entrant walking across the beam without flaw, besting Simone Biles after she defies gravity, physics, and our basic understanding of human capacity).
But what if we considered a salesperson’s performance in excess of or in arrears of the expectations defined by such a simple model? How many more or fewer deals did you close than we might have expected, given the prices offered? All that is required is an inversion of the sigmoid function above, a little calculation of “true wins,” and some assessment of the salesperson’s performance above or below expectation.
AE clients (and clients everywhere else too, we presume!) face such challenges in industries of all shapes and sizes. Solving a problem begins with an understanding of what might have happened without intervention - in other words, a view unclouded by recent highs and lows. What if Ron Popeil failed to sell his Chop-O-Matic to the first three customers to whom he spoke...and as a knee-jerk reaction, his father fired him? AE works with clients to assess results in their proper context. What if Ron’s first three customers just hated vegetables? (P.S. You could be one of those clients if you reach out to us!)
This is how we, at AE, see the world. Not just as machine learning models and accuracy statistics (e.g. wins and losses), but in terms of baseline expectations. We help our clients see opportunities, and maintain growth mindsets by focusing on more than simply the most recent tangible outcome. Remaining agile, and actually adhering to Agile means adapting in the short-term while observing the broader picture (and enjoying some banter along the way!).
During my dalliances in staid corporate environs, I found myself engaged in a debate reminiscent of fantasy football discourse of yesteryear. Admittedly, the verbiage contains fewer insults directed at the attributes of bodily orifices of matriarchs. Yet, that business, like so many others, generates its revenue via annual subscriptions. Those subscriptions, as they approach their date of expiry, after which renewal occurs...or not. Prospective clients are approached and converted...or not. Business development associates are evaluated, unsurprisingly on conversion rates and retention rates, just as fantasy football managers are evaluated on their winning percentage (and their derisive creativity). Of course, at no point does anyone assess the relative difficulty of the renewal! Clients who have long since soured on the product and barely engage with the brand, generally do not renew. Clients who love the product and have used it daily for a decade almost always sign up for more. Explain to me why exactly the BD employee who manages the second client’s account gets credit for the same number of “wins” as the one managing the first?
The admonishment is simple—set a baseline, then, and only then, evaluate what actually transpired. Perhaps the number of features that define the probability an account is retained next year is greater than one...but then, that’s just a sigmoid with more than one variable involved (a.k.a. logistic regression, available in python, R, Excel, and wherever else fine corporate tools are sold!).
In fantasy football, pricing, conversion, and anywhere else the words “win” and “loss” might seem appropriate to overly competitive humans, a fair assessment of the competitors demands an assessment of baseline expectations. And that is the purpose of our friend, the sigmoid function. At AE, when we begin a data science journey, we set expectations. We assess models beyond knee-jerk reactions to recent wins and losses. Most importantly, we educate clients to apply this thinking early and often in their own business lives. Of course, if after all of this, you still find yourself suffering through another maddening Sunday of fantasy football, well, perhaps you really do deserve a better fate, the gridiron gods truly have frowned upon you, and your opponent’s mother is truly of unusual size.
We'll show you our fantasy football team if you show us yours. Let's talk draft.
No one works with an agency just because they have a clever blog. To work with my colleagues, who spend their days developing software that turns your MVP into an IPO, rather than writing blog posts, click here (Then you can spend your time reading our content from your yacht / pied-a-terre). If you can’t afford to build an app, you can always learn how to succeed in tech by reading other essays.
Settling Arguments With Baseline Expectations
Adjusting your baseline expectations could relieve your fantasy football woes. A data scientist explains why you should take a new approach to this season's draft.
This is a sigmoid function:
Why the hell should anyone care about sigmoid functions? After all, we’re talking about some little exponential in a denominator. To most, it resembles what you might see before you fall asleep, begin texting, ogling that member of your statistics class, or entering catatonia from one-too-many horrific note-taking experiences. The answer, apart from “because I said so,” “because you’ll make more money someday if you do,” and “because failing tests and retaking classes generally sucks,” is that it can help settle arguments. No, seriously.
For the data scientists in the audience, the sigmoid function might be a quaint reminder of the early days of neural networks—back when deep learning meant preparing for an essay on Faulkner rather than the sound and fury of AI-obsessed VCs...or the building block of perceptrons and other activation functions. But we’re talking to the other folks in the crowd. You may also remember its roles in such films as logistic regressions, cumulative distribution functions, and softmax. Schedule a call to hear our data scientists reminisce more.
For those of us who drink beer and watch football on Sundays, who pronounce the word ‘sandwich’ with two ‘ms’ and no ‘w,’ sigmoids are simple little functions that typically traverse the well-worn path from 0 to 1, slowly, then abruptly, then slowly again.
They look like this:
Sigmoids settle arguments. Why? Because they encourage us to consider what “should have happened” rather than what did. The totality of any sports bettor’s tortured existence can be summarized as a litany of things that were likely that did not occur, or things that are unlikely, but occurred nonetheless. Fantasy football generates such arguments multiple times weekly throughout football season and rends lifelong friendships with such rationalizations. In other words, everyone claims they were unlucky and their opponents were blessed with an embarrassment of riches in the form of fortuitous breaks. But such discourse is tedious to the football fanatic turned data scientist. And thus, as the commissioner of one particular league since 2010 (I entered the league in the fall of 2004, back when we’d assemble on the stained couches of some dorm, select players, then manually send the results to Yahoo via a badly-frayed ethernet cord), I took it upon myself to address this issue.
For those who spend their weekends doing useful things around the house or engaging affably with significant others and spouses (my apologies to my wife), fantasy football is fairly simple. Teams are filled with real-life players, and from their weekly performances, points are amassed. Each week, within a league, teams face a single opponent, and the team with the higher number of points wins. At this point various forms of derision regarding the vanquished opponent’s intelligence and the corporal attributes of their mother are customary.
Now, in a league with twelve teams, how well one’s team plays is often secondary to who one’s team plays. The team with the 2nd-highest score in a league on a given week is still tagged with a loss (and the aforementioned insults regarding their mother) if they are unfortunate enough to be matched with the team that earns the week’s highest score. Conversely, the team with the 2nd-lowest score is still empowered to disparage to their heart’s content if they are fortunate enough to face the team with the week’s lowest score.
As the season unfolds, these narrow escapes and “bad beats” form a narrative wherein there are not only winners and losers, but also those upon whom fortune has smiled and those upon whom the ominous, darkened clouds surrounding the accursed have gathered. Somewhere, after a couple potent potables on a cold, December night, invariably, some group email is penned regarding the continued (read: unfair) luck of one such roster and the continued (read: unfair) misfortune of their own.
What if, amassing samples of previous games, we could determine the “true” probabilities of a team winning its weekly matchup, given a certain number of points scored? What if, in so doing, we removed the vicissitudes of who played whom when? This would reveal the “true standings,” that is, those produced in a fairer world. So perhaps this is not the “best of all possible worlds,” but then, Voltaire never played fantasy football.
Every week, games occur, points are amassed, and, ultimately, wins and losses are assigned. Much like a logistic regression aspires to select a probability based on binary outcomes, a sigmoid function is fit to historical scores and the wins and losses they generated. Below are the results from two years of the aforementioned fantasy football league:
The red dots represent the scores of individual teams, where the outcome was a loss. The blues denote wins. What pattern appears? Clearly, the red dots generally occur at lower values than the blue dots (“duh, higher scores are more likely to win”). However, as Damon Runyon once said (stealing the words of Hugh Keough, who in turn was basically cribbing from Ecclesiastes), “the race is not always to the swift, nor the battle to the strong, but that is the way to bet!” So, if we look at the dots between 140 and 160 points, most are blue. If we look at the dots between 80 and 100, most are red. But it is these expectations that spark incendiary commentary and the type of angst that lingers for years in the minds of the fanatical. When your team scores 130 points, you expect to win. When your rival scores 90, you expect him or her to lose. Yet, there are blue dots around 90 and red dots around 130. And thus begin soliloquies on the injustice of it all.
So what do we do about this? Well, we do the thing that data scientists do—we build a model. Adding a nugget of complexity to our humble sigmoid, we fit the following:
In the equation, p denotes the number of points scored, c, the center of the sigmoid (that is, the point at which the probability is 0.5), and 𝜶 essentially describes how steeply the curve ascends as we move from left to right.
In turn, every score corresponds to a probability of winning—and we assign each team that number of wins. In the chart below, a score of 125 points yields around a 75% probability of victory. And thus, we assign that team 0.75 “true wins,” rather than the 0 or 1 that are actually obtained. We do this all season long and two quantities emerge:
- The “true standings” - each team’s record, in a truly just world is easily obtained after n games have been played, each with points scored pi, via:
2. The aggregated “luck,” positive or negative, of each roster (wins above expectation), after n games, is simply:
Where:
In this case, the values of yi simply represent what actually happened (1 for a win, 0 for a loss).
For example, one Sunday, your team scores 125 points...and wins. The value for E[wins] is ~0.75, the value for E[losses] is ~0.25. The value for yi is 1 (you really did win), and “Luck” is now 1 - 0.75 = 0.25. Had you lost, would have been 0, “Luck” would have been 0 - 0.75 = -0.75. Just as you earn expected wins, you amass expected luck (or “unluck” in the case of a negative value).
Why does this matter, apart from minimizing sordid condemnations of maternal virtues? Because entities in the “real world,” (you know, the ones tasked with generating profits rather than winning fantasy football games) fixate on what happened with little consideration for the relative likelihoods of alternative outcomes. Even in a world awash in data scientists, engineers, and dozens of other titles containing some variant of the word “analytics,” we are drawn inexorably to the outcomes we observe.
Once, during my young adult delinquency (as a corporate consultant), I found myself managing a couple young analysts on a project, during which a client was assessing the efficacy of salespersons. In some regards, salespeople were, are, and will continue to be judged on the number of deals they close relative to the number they attempt to close, rather than the likelihood of closing the deal as a function of the price offered to the prospective client. To wit, if the salesperson gives away the farm in the form of an extremely generous price, the client is more likely to say yes than if they hold the line. Counting wins and losses in such an environment is akin to evaluating an Olympic gymnast without considering the routine’s degree of difficulty (imagine some Micronesian entrant walking across the beam without flaw, besting Simone Biles after she defies gravity, physics, and our basic understanding of human capacity).
But what if we considered a salesperson’s performance in excess of or in arrears of the expectations defined by such a simple model? How many more or fewer deals did you close than we might have expected, given the prices offered? All that is required is an inversion of the sigmoid function above, a little calculation of “true wins,” and some assessment of the salesperson’s performance above or below expectation.
AE clients (and clients everywhere else too, we presume!) face such challenges in industries of all shapes and sizes. Solving a problem begins with an understanding of what might have happened without intervention - in other words, a view unclouded by recent highs and lows. What if Ron Popeil failed to sell his Chop-O-Matic to the first three customers to whom he spoke...and as a knee-jerk reaction, his father fired him? AE works with clients to assess results in their proper context. What if Ron’s first three customers just hated vegetables? (P.S. You could be one of those clients if you reach out to us!)
This is how we, at AE, see the world. Not just as machine learning models and accuracy statistics (e.g. wins and losses), but in terms of baseline expectations. We help our clients see opportunities, and maintain growth mindsets by focusing on more than simply the most recent tangible outcome. Remaining agile, and actually adhering to Agile means adapting in the short-term while observing the broader picture (and enjoying some banter along the way!).
During my dalliances in staid corporate environs, I found myself engaged in a debate reminiscent of fantasy football discourse of yesteryear. Admittedly, the verbiage contains fewer insults directed at the attributes of bodily orifices of matriarchs. Yet, that business, like so many others, generates its revenue via annual subscriptions. Those subscriptions, as they approach their date of expiry, after which renewal occurs...or not. Prospective clients are approached and converted...or not. Business development associates are evaluated, unsurprisingly on conversion rates and retention rates, just as fantasy football managers are evaluated on their winning percentage (and their derisive creativity). Of course, at no point does anyone assess the relative difficulty of the renewal! Clients who have long since soured on the product and barely engage with the brand, generally do not renew. Clients who love the product and have used it daily for a decade almost always sign up for more. Explain to me why exactly the BD employee who manages the second client’s account gets credit for the same number of “wins” as the one managing the first?
The admonishment is simple—set a baseline, then, and only then, evaluate what actually transpired. Perhaps the number of features that define the probability an account is retained next year is greater than one...but then, that’s just a sigmoid with more than one variable involved (a.k.a. logistic regression, available in python, R, Excel, and wherever else fine corporate tools are sold!).
In fantasy football, pricing, conversion, and anywhere else the words “win” and “loss” might seem appropriate to overly competitive humans, a fair assessment of the competitors demands an assessment of baseline expectations. And that is the purpose of our friend, the sigmoid function. At AE, when we begin a data science journey, we set expectations. We assess models beyond knee-jerk reactions to recent wins and losses. Most importantly, we educate clients to apply this thinking early and often in their own business lives. Of course, if after all of this, you still find yourself suffering through another maddening Sunday of fantasy football, well, perhaps you really do deserve a better fate, the gridiron gods truly have frowned upon you, and your opponent’s mother is truly of unusual size.
We'll show you our fantasy football team if you show us yours. Let's talk draft.